
Llegamos a la segunda parte de este curso de manejo de archivos txt con Python. Puedes ver la primera parte aquí.
En esta ocasión, te voy a mostrar como escribir en los archivos txt con Python y como manejar ciertas tareas de codificación de caracteres, así como la detección del lenguaje de escritura del archivo.
Escribir en archivos txt con Python
Llegamos al siguiente modo, el de escritura. Con este modo, podremos realizar cambios en archivos txt y guardarlos.
Crear archivos txt desde Python
Cuando utilizamos el modo escritura ("w") con with open, si un archivo existe, reemplazamos todo su contenido y si no existe. Lo crea. Empecemos eliminando el archivo txt de pruebas. Vamos a crearlo de nuevo con with open().
with open("test.txt", "w") as archivo:
archivo.write("Esta es una línea escrita en el archivo.")Al hacer esto, si no has eliminado previamente el archivo llamado "test.txt", lo habrá sobreescrito con el string que le he pasado en el "archivo.write()".
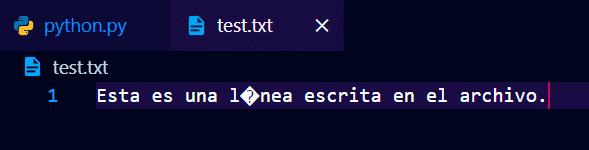
Aparece con problemas de codificación en los acentos, de nuevo.
Así, que vamos a solucionar el fallo que llevamos desde el principio.
Codificación para trabajar con acentos con archivos txt en Python
Una forma de solucionar los problemas de codificación con los archivos, es añadir al with open, el argumento "encoding" y darle un valor de "utf-8". Esto nos sirve para el modo lectura y escritura.
with open("test.txt", "r", encoding="utf-8") as archivo:
print(archivo.read())Sin embargo, al intentar leer el archivo en codificación utf-8, me da el siguiente error:
Error en la consola
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xed in position 13: invalid continuation byte
Este error es producido, porque antes, he creado el archivo con with open() "w", sin indicar codificación alguna, lo que ha hecho, que se cree con codificación "ISO-8859-1".
Ver codificación de los archivos
Cuando queremos saber qué tipo de codificación tiene un archivo de texto, podemos utilizar el módulo chardet.
Instalar chardet de Python
Para instalar chardet, solo tienes que ejecutar el siguiente comando en la terminal:
pip install chardet
Importar chardet
Para importar chardet solo tienes que hacer este import:
import chardet
Lo siguiente que haremos, será abrir el archivo en modo lectura de bytes "rb".
Leer archivos txt en modo lectura de bytes en Python
El modo lectura de bytes (read bytes), es un modo para leer el contenido de un archivo como secuencia de bytes, en lugar de leerlo en caracteres, como hacía el modo de lectura normal.
import chardet
with open('test.txt', 'rb') as archivo:
resultado = chardet.detect(archivo.read())
print(resultado['encoding'])Resultado en la consola
ISO-8859-1
¿Cómo funciona chardet?
Lo primero, es abrir el archivo en modo lectura de bytes con el modo "rb".
Utilizamos el método detect() de chardet con el archivo abierto. Este método, se encarga de analizar el contenido y en base a los resultados, arroja una codificación.
Si imprimes la variable "resultado" sin ninguna clave, verás que devuelve un diccionario como este:
import chardet
with open('test.txt', 'rb') as archivo:
resultado = chardet.detect(archivo.read())
print(resultado)Resultado en la consola
{'encoding': 'ISO-8859-1', 'confidence': 0.73, 'language': ''}
La parte de encoding, nos dice la codificación del archivo. La parte de confidencia, el nivel de confianza de la detección con un valor del 0 al 1, siendo 1 el 100% de confianza.
En este ejemplo, el algoritmo está un 73% seguro de que es esa codificación.
Este nivel de confianza, puede servirnos para que se tomen ciertas acciones en base a cierto nivel de confianza.
Después, la parte del lenguaje, está para detectar en que lenguaje está escrito el archivo. Sin embargo, chardet no lo hace de forma nativa, requiere de la combinación con otro módulo.
Instalar langdetect en Python
Para instalar langdetect en Python, solo tienes que poner el siguiente comando en la terminal:
pip install langdetect
Importar langdetect
Del módulo langdetect, solo vamos a importar su función "detect".
from langdetect import detect
Ahora, pon el siguiente código para detectar la codificación, la confiabilidad y añadir el valor devuelto por langdetect a la clave de diccionario 'language' de chardet.
import chardet
from langdetect import detect
with open('test.txt', 'rb') as archivo:
contenido = archivo.read() # Se lee el archivo
resultado = chardet.detect(contenido) # Se crea el diccionario de chardet.detect()
lenguaje = detect(contenido.decode(resultado['encoding'])) #Utilizamos el método detect() de langdetect
resultado['language'] = lenguaje # Se le añade el resultado al diccionario de chardet
print(resultado) # Comprobamos el resultadoEn el archivo txt, pongo lo siguiente:
Programación Fácil es un sitio web para aprender programación.
Resultado en la consola
{'encoding': 'utf-8', 'confidence': 0.87625, 'language': 'es'}
Establecer codificación en UTF-8 para los archivos TXT con Python
Si quieres que los archivos se creen directamente en codificación UTF-8, es tan sencillo como establecerlo en el with open al crearlo:
import chardet
from langdetect import detect
with open("test.txt", "w", encoding="utf-8") as archivo: #Creamos el archivo en codificación utf-8
archivo.write("Programación Fácil es un sitio web para aprender programación.")
with open('test.txt', 'rb') as archivo:
contenido = archivo.read() # Se lee el archivo
resultado = chardet.detect(contenido) # Se crea el diccionario de chardet.detect()
lenguaje = detect(contenido.decode(resultado['encoding'])) #Utilizamos el método detect() de langdetect
resultado['language'] = lenguaje # Se le añade el resultado al diccionario de chardet
print(resultado) # Comprobamos el resultadoResultado en la consola
{'encoding': 'utf-8', 'confidence': 0.87625, 'language': 'es'}
Seguimos en el siguiente capítulo con más tareas para el manejo de archivos txt desde Python.
No te pierdas nada del curso Máster en Python.
